
The National Institutes of Health (NIH) recently made history. Its All of Us Research Program is officially the largest and most diverse integrated genomics and health database in the world. With longitudinal data from over 633,000 participants (aiming for over a million), it is a goldmine for precision medicine, clinical trials, and drug discovery startups.
But for the biotech and AI companies eager to use this dataset, there is a quiet, frustrating truth:
Raw data is completely useless to a machine learning pipeline. Between downloading the NIH’s raw datasets and actually feeding clean, structured features into an ML model lies a massive, expensive, and time-consuming "Ingestion Tax."
Typically, clinical-stage companies turn highly paid machine learning engineers and data scientists into manual "data janitors." These teams spend weeks writing and debugging fragile, custom ETL scripts just to align third-party data structures with their internal schemas.
In this article, we'll look at why consuming third-party datasets is a "square peg, round hole" problem, walk through a concrete biotech use case, and show how Elvity automates the entire ingestion process—with zero manual coding, automatic schema adaptation, and FDA-grade cell lineage.
The "Square Peg, Round Hole" Challenge of Third-Party Data
To maintain scalability and research standards, the NIH organizes its clinical data using the OMOP Common Data Model (v5.3). Under the hood, this is a highly normalized relational database structure stored in Google BigQuery, consisting of specialized tables like person, condition_occurrence, drug_exposure, and measurement.
Additionally, the program integrates custom, non-OMOP tables to capture wearable device data, such as Fitbit logs (heart_rate_summary and sleep_level).
While this is an elegant way to store data nationally, it is highly inconvenient for a biotech startup whose ML model expects a flat, patient-level feature matrix.
Meet Aura Therapeutics: A Concrete Use Case
Imagine Aura Therapeutics, a startup training a machine learning model to predict cardiovascular stress in cancer patients undergoing immunotherapy.
To feed their model, Aura’s data pipeline requires a clean, flat table (their Target Schema) that looks like this:
| Patient_ID | Cancer_Dx | Active_Drug | Avg_Resting_HR | Sleep_Hrs | Smoker |
|---|---|---|---|---|---|
| Internal Hash | Clean Text | RxNorm Name | Float | Float | Boolean |
To get this simple 6-column matrix out of the raw NIH database, Aura's engineers must execute a grueling data-wrangling sequence:
- Relational Joins: Join
personwithcondition_occurrence(filtering for specific cancer SNOMED codes) anddrug_exposure(for immunotherapies). - Vocabulary Decoding: Translate abstract, raw concept IDs (e.g., SNOMED Code
363346000is "Malignant neoplastic disease") into human-readable strings. - Wearable Alignment: Parse thousands of lines of messy time-series Fitbit logs (
heart_rate_summary), calculate average heart rates, and align them to the patient’s clinical timeline. - Survey Extraction: Parse nested, multi-choice survey responses to extract smoker status.
In a traditional setup, Aura's engineers would spend weeks writing custom Python/Pandas scripts to handle this. Let's look at how Elvity solves this problem across three critical pillars.
Pillar 1: Zero-Prompt Automated Schema Mapping
The core philosophy of Elvity is simple: You shouldn't have to write code to align data.
Instead of writing complex SQL queries or programming python scripts, Aura’s engineering team simply uploads their desired Target Schema (the flat, 6-column ML matrix) into the Elvity Data Portal.
Elvity's autonomous AI data engine automatically analyzes the raw NIH tables and Fitbit files, identifies the relationships, and builds a deterministic mapping plan behind the scenes.
- No prompt engineering is required.
- No manual column matching is needed.
- The system handles the multi-table relational joins and flattens the wearable time-series logs automatically.
Pillar 2: Overcoming Ingestion Friction & Schema Drift
Raw, third-party clinical and wearable datasets are notoriously inconsistent and messy. If fed directly into a machine learning model, they will corrupt the training results. Elvity’s engine cleans and normalizes this data automatically during the mapping phase:
1. Timezone Normalization
EHR clinical data is typically recorded in the hospital's local timezone, while Fitbit data is recorded in the participant’s local time based on their physical location. Elvity automatically detects this timezone metadata and standardizes all timestamps to a single target timezone (e.g., UTC) so clinical events and wearable heart rate spikes align perfectly on the same timeline.
2. Outlier and Noise Filtering
Wearable sensors glitch. Fitbit logs regularly contain impossible rows with a heart rate of 0 bpm or sleep durations of 24 hours. Elvity runs advanced, custom validation rules (e.g., assert heart_rate between 40 and 200) during ingestion, automatically flagging, smoothing, or quarantining bad sensor rows before they contaminate Aura's ML models.
3. Vocabulary Translation
The NIH database stores drug entries as raw OMOP Concept IDs (e.g., 40239266 for Pembrolizumab). Elvity’s engine automatically executes medical vocabulary translations, mapping standard OMOP IDs directly to Aura’s internal clinical dictionaries and drug classes on the fly.
4. Self-Healing Schema Drift
The NIH regularly updates its Curated Data Repository (CDR) with new releases, which can result in database restructures or column renames. Furthermore, if Aura's internal engineering team decides to update their own target schema (e.g., adding a new HRV_baseline biomarker column), a traditional ETL pipeline would crash.
With Elvity, the pipeline is self-healing:
- NIH Upstream Updates: If the NIH releases a new CDR version that changes a column name (e.g., from
heart_rate_valuetopulse_bpm), Elvity's fuzzy-matching AI auto-patches the pipeline recipe and resumes ingestion with zero downtime. - Internal Changes: If Aura updates their Target Schema, they simply upload the new schema file, and Elvity automatically rescans the NIH source tables to map the new variables instantly.
Pillar 3: FDA-Grade Cell Lineage and Auditability
In Biotech and digital health, you cannot operate a "black box" data pipeline. Under FDA regulations (like 21 CFR Part 11) and modern healthcare standards, any clinical decision support AI must be explainable and fully auditable.
If Aura's ML model predicts that Patient #9821 is at risk of cardiotoxicity from an immunotherapy drug, researchers and regulators must be able to audit that prediction. They have to prove that the data used to train the model was accurate and untampered with.
Tracing a single cell in a flattened 1,000,000-row training table back to its exact source row in a massive, multi-table BigQuery or Fitbit download is a classic "needle in a haystack" problem.
Elvity solves this with Cell-Level Lineage. Here is how it works in practice:
- Inspect the Target Table: A researcher views Patient #9821's clean data row in Elvity's Smart Data Grid and notices their average resting heart rate is recorded as 72.4.
- Hover to Trace: The researcher simply hovers over the "72.4" cell, which triggers an interactive, visual data provenance overlay.
- Access Source Metadata: Elvity instantly displays the exact raw source coordinates: the specific rows in the raw
heart_rate_summary.csvFitbit log and the corresponding row in the BigQuery OMOPmeasurementtable.
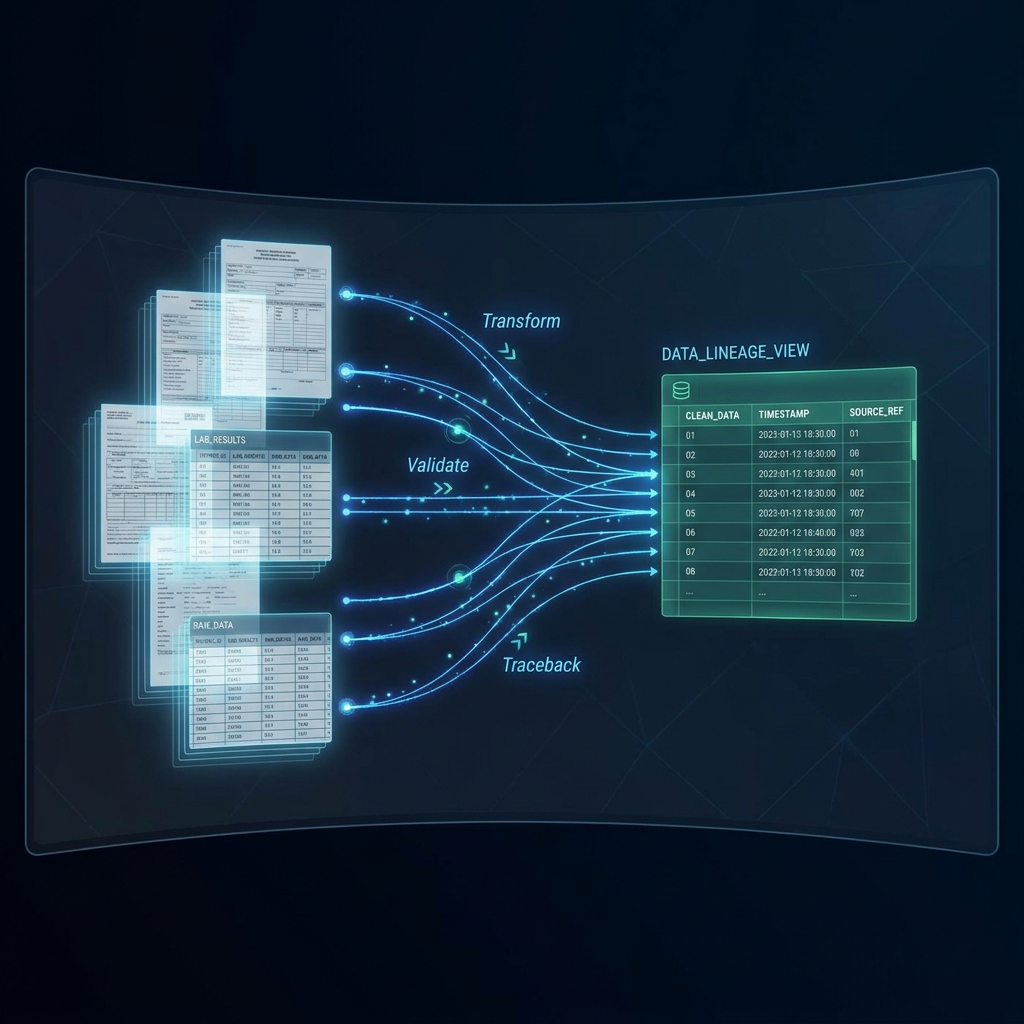
Every single cell in the final, clean target table is physically linked to its source coordinates. This provides a bulletproof, FDA-ready audit trail of data provenance—essential for clinical trials, peer-reviewed scientific journals, and regulatory submissions.
Unlocking the Full Value of External Data
The NIH's All of Us dataset represents the future of precision medicine, but its potential is locked behind a massive technical integration barrier.
By automating schema mapping, normalizing complex clinical and wearable datasets on the fly, and providing complete cell-level auditability, Elvity removes the "Ingestion Tax."
We let your data scientists stop acting as "data janitors" and get back to what they do best: building the algorithms that save lives.
Are you ready to see how Elvity can accelerate your external data ingestion?
Learn more and request a demo at www.elvity.ai or reach out to our team to discuss your target data schemas today.